


Wed, Sep 13, 2023




Today marks a significant milestone for us at Tryolabs as we introduce Temporian.
In collaboration with Google, we've designed this tool to address the multifaceted challenges of temporal data processing head-on. Let's explore the inspiration, functionality, and future of Temporian.
In the world of data science, our experience working with clients has made it abundantly clear that temporal data is everywhere, powering a wide range of use cases and applications. From sales forecasting, fraud detection, and marketing optimization to processing signals from electronic sensors, the challenges presented by temporal data are very diverse. Whether dealing with long time sequences spanning years or precise millisecond measurements, efficiently handling temporal events is an essential asset.
Typically, generic data science tools are employed to tackle temporal data manipulation. While many of these tools are versatile enough and can be adapted to perform mostly any data transformation, the number of steps and intricacies required to handle some particular cases often leads to large codebases, especially as projects grow in complexity. This quickly becomes a challenge, often leading to finicky data manipulations, code subtleties, hidden behavior, and bugs. On top of that, inefficient computation becomes commonplace when using tools and operations that were not designed for their original purpose.
Recognizing the need for a specialized solution for this domain, we partnered with Google to develop Temporian: a world-class, open-source Python library for preprocessing and feature engineering of temporal data.

At its heart lies a clever use of proper data structures and formats, specially designed to handle temporal data in all its forms. By representing data as a generic collection of events with corresponding timestamps—potentially originating from multiple sources, having multiple attributes, and being non-uniformly sampled—Temporian seamlessly adapts to a wide array of temporal data formats. Furthermore, it leverages highly optimized C++ operations underneath, and we have an active development lane to leverage Apache Beam's capabilities for running operations on large-scale data.
Temporian being purpose-built for temporal data manipulation brings numerous benefits, including streamlined temporal data operations and code that is clear, intuitive, and easy to maintain. As a result, it minimizes the likelihood of bugs or hidden behavior, also providing substantial computational efficiency gains.
Not less important, it integrates with the most popular data science and Machine Learning tools. Its user-centered documentation provides comprehensive tutorials, enabling effortless initiation with Pandas and TensorFlow. From exploratory data analysis in interactive notebooks to deploying robust high-volume processing pipelines, Temporian is geared to facilitate the entire spectrum.


The story behind our collaboration journey
How did the paths of Tryolabs and Google converge in the vast landscape of Machine Learning and data science? The answer lies in a shared aspiration and a mutual recognition of each other's strengths. At Tryolabs, forecasting is one of our main areas of expertise—having applied it to solve real-world use cases that range from Predictive Maintenance of Oil Pipes to Pricing Optimization - and as such, we know first-hand that a purpose-made temporal data preprocessing tool would bring tons of value to the table, especially when it comes to ease of development and time to market of such solutions. Add to that Google’s need for a tool capable of processing zettabytes of data from millions of events worldwide in real-time, and you get both a perfect goal to strive for, and two engineering teams with more than enough expertise to take a swing at it!
On top of that, we are no strangers to open-source development, with our home-grown Norfair being one very successful example. Neither is it the first time that we collaborate with Google, since that time we streamed together a live-chat event with some of the Swift for TensorFlow’s core developers, sharing our experience as early users of the library. They were incredibly humble and awesome, and we enjoyed the experience so much that we came back for more.

Temporian’s journey began almost a year ago, when the teams got together to brainstorm what would be the most valuable features in the solution we aimed to build. From then we underwent a large phase of design, followed by the development of an MVP which was then validated via UX testing with real users. After having made adjustments based on the received feedback, and polishing up and publishing the documentation for the library, we finally decided to publish it for its first-ever users to have a go with it. This is only the start - there’s a long road ahead for Temporian, and we’ll be there for it!
The library’s development was not without its challenges—needing, for example, to strike a precise balance in exposing a public API that was simple and intuitive for new users but flexible and powerful enough for advanced ones, to support several execution backends for each available operation, and to quickly become proficient in tools that we’d never crossed paths with. Although challenging, overcoming those and many other issues was little but a learning instance that we gladly embraced—and a breeze to go through when surrounded by teammates with the collective experience of our own.
Inside Temporian: a deep dive into its capabilities
So: what exactly does Temporian do? And more importantly, what sets it apart from the myriad of other widely adopted and maintained data preprocessing libraries?
A very simple example of a Temporian script. The snippet calculates the weekly sales for each store, visualizes the output with a plot, and exports the data to a CSV file.
Unlike most data preprocessing libraries, Temporian was designed and built with temporal data—and temporal data only—in mind.
That is, Temporian was built to handle the timestamps associated with each of your data points natively, and that enables it to run certain operations on them much, much more efficiently, both in terms of time and memory - in some cases reaching x1000 speedups compared to the same preprocessing written directly in NumPy! Note that this is by no means because of NumPy being slow or inefficient—it just wasn’t built for temporal data (and, as a matter of fact, Temporian heavily relies on it under the hood!).
These results are only made possible by Temporian’s custom data structure, called the EventSet, which arranges temporal data in a way that makes it efficient to operate on it, and to great portions of Temporian’s operations being implemented in C++ and highly optimized.

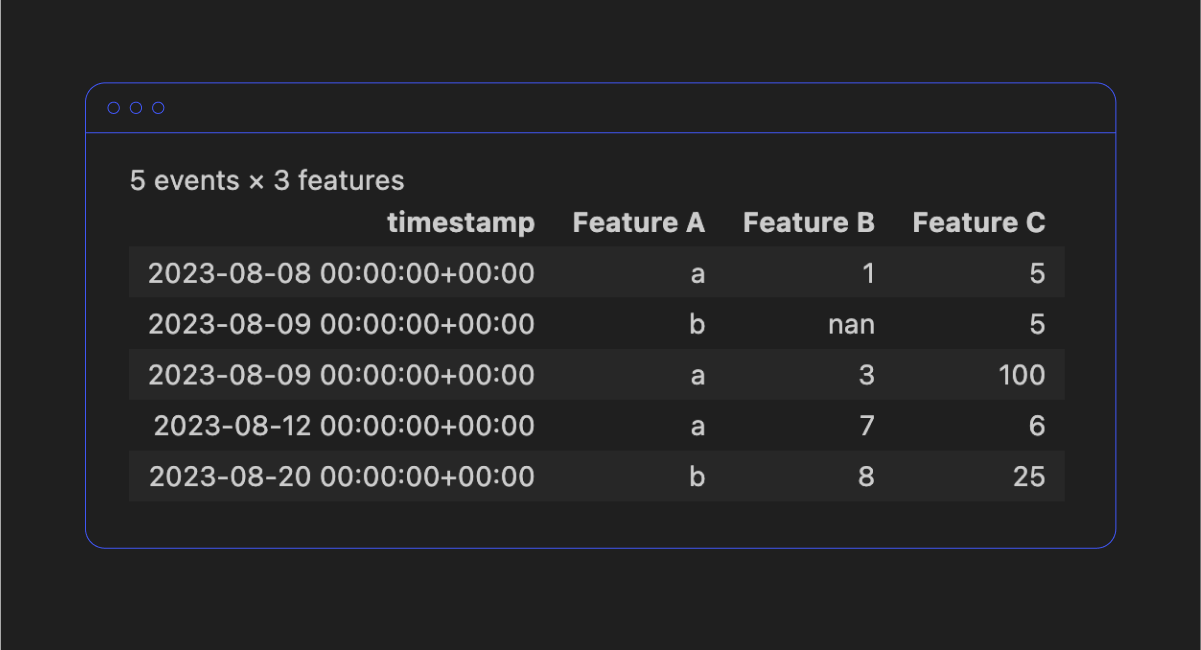
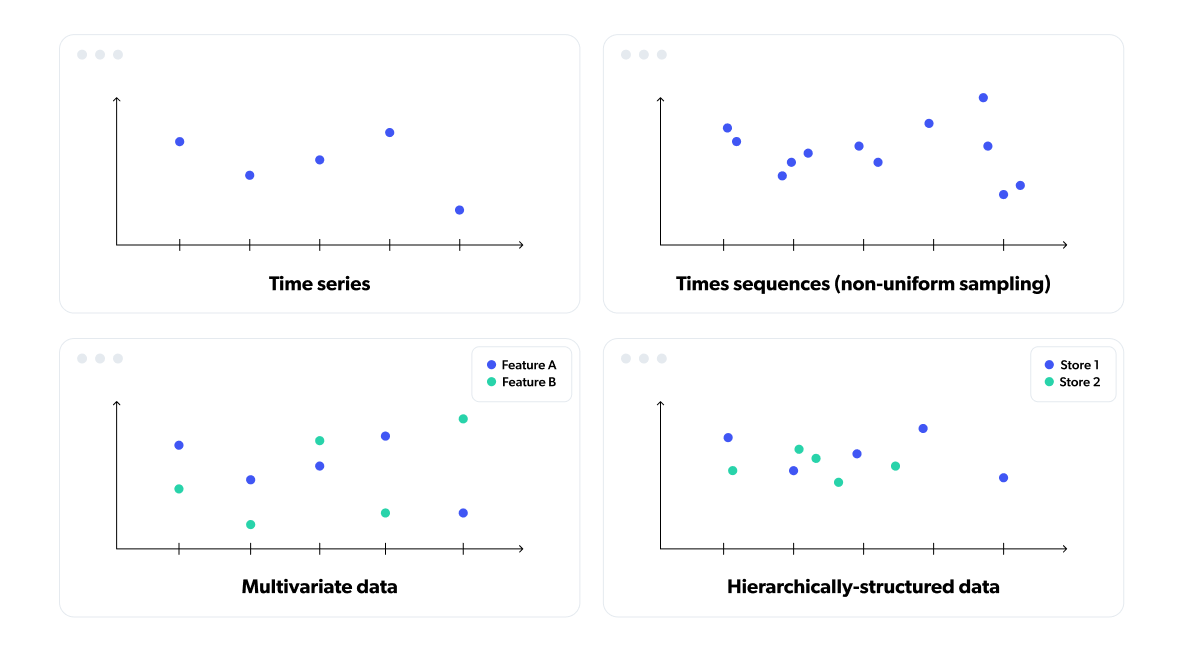
Temporian’s EventSet isn’t just able to represent time series (which can be defined as uniformly-sampled temporal data, or a series of values that happen sequentially and with equal intervals between them), but also multivariate and hierarchically-structured data, and data with non-uniform and non-aligned sampling, which by itself sets it apart from any alternative libraries that we know of.

You may be wondering exactly what operations Temporian provides. The library’s API Reference hosts the complete list of available operators (which is growing by the day!), but in short, Temporian offers a battery of time-related functions, that allow users to compute features as simple as the day of the month an event occurred on, to as complex as the moving standard deviation of the sales of each product in your online store, in relation to the lagged cumulative sum of sales across all products since launch.
To top it all off: a Temporian program can be developed iteratively in an interactive development environment, such as a Jupyter notebook, and then saved to a file to be run in Apache Beam on production-grade workflows! This is only possible thanks to Temporian tracking the operations a user performs on their data and maintaining an underlying graph of operations - all in a transparent way to most users!
Real-world scenarios
Temporian can be helpful in any domain where temporality plays a role… Which is just about all of them?
Jokes aside, temporal data is as commonplace in AI as you get, and can come up in the form of transactions, user events, logs, product sales, medical data, sensor signals, or weather patterns - just to name a few. And in each of those use cases, Temporian can lend a huge hand when it comes to consuming the raw temporal data and outputting something a Machine Learning model can work with!

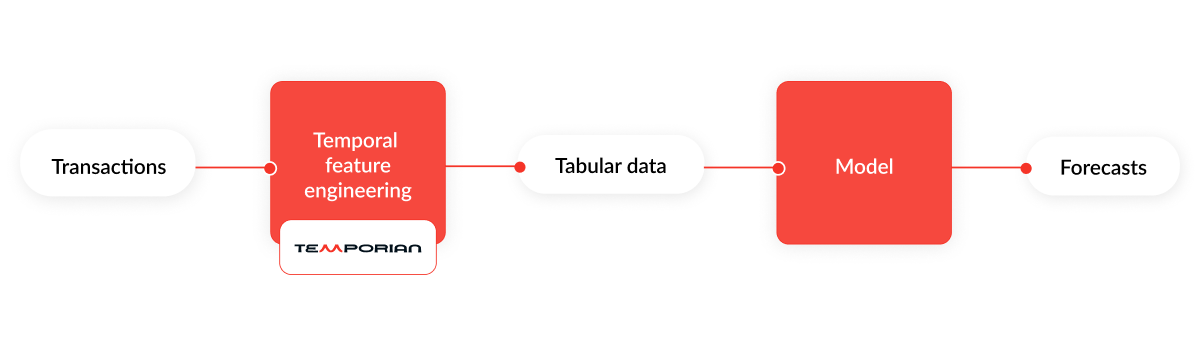
Not sold yet? Check out how Temporian deals with a real-world scenario in the M5 Competition tutorial, which uses Temporian to preprocess and feature engineer hierarchical sales data from Walmart stores across the US. Its output is then fed to a Gradient Boosted Trees model to reach near state-of-the-art performance on forecasting future sales!
This tutorial gives a good overview of Temporian’s versatility. The competition’s data is loaded into three Temporian EventSets, which are used to compute a variety of temporal features:
- Past sales: the lagged sales values from the last couple of days, computed using
lag(). - Moving statistics: the average and standard deviation of sales in the last couple of weeks, computed using
simple_moving_average()andmoving_standard_deviation(). - Calendar data: the day of the week, day of the month, and month associated with each date we want to forecast on, computed using
calendar_day_of_week(),calendar_day_of_month(), andcalendar_month(). - Sales aggregated per department: the sum of sales in each product’s department during the last month, computed using
drop_index(),moving_sum(), andpropagate(). - Special events: the number of days remaining until key calendar events, such as Christmas or Father’s Day, computed using
propagate(),leak(), andresample().
Note that Temporian not only makes it easy for the developer to write the code to compute these features but also executes it extremely efficiently, delegating as much processing as possible to C++ and minimizing memory usage, which can make or break your program when dealing with large amounts of data!
If you want other examples of Temporian at work (or just can’t wait to dive right into the code), check out the Getting Started guide for a simple step-by-step example, or one of the featured tutorials for Detecting payment card fraud, Heart Rate Analysis, and Loan Outcomes Prediction!
Kickstarting your Temporian experience
The best place to start your journey as a Temporian user is the library’s docs, which provide all kinds of resources for new and advanced users, including a Getting Started tutorial, a quick intro to how the library works, a full tour of its concepts and capabilities, and the complete API Reference for the library’s components.
If instead you’re more of a hands-on learner and can’t wait to get started: Temporian is available on PyPI and can be installed with a simple pip install temporian (though we do recommend checking out some of the introductory guides first!).
Embracing open-source, community, and the future
This exciting collaboration between Tryolabs and Google holds greater significance since we're creating an open-source library, accessible for use and improvement by anyone worldwide. We know for a fact that the best solutions emerge when the collective intelligence of the community comes together, and thus, we welcome experts and developers alike to give it a try and join forces with us!
Now is the perfect time to get involved as a user, developer, or early adopter, helping us showcase the library in real-world scenarios. With an increasingly stable API and comprehensive, well-tested documentation, at this point you can confidently explore and leverage Temporian's capabilities. Moreover, user feedback and feature requests will play an important role in shaping the library's future, ensuring that it continuously evolves to meet the needs of data scientists, engineers, researchers, and all potential users.
Looking ahead, our roadmap is ambitious and promising. We will continue to develop Temporian, expanding its capabilities with more operators, enhancing Apache Beam and cloud providers integration, and supporting real-time streaming applications. Staying focused on temporal data preprocessing and feature engineering, we aim to become the go-to library for industry projects at all scales.
We are thrilled to be on this journey, creating a top-notch tool that bridges a crucial gap in the data science landscape. We invite you all to join us in making Temporian the perfect solution for temporal data processing!
Wondering how AI can help you?

© 2024. All rights reserved.